




We've figured out why ChatGPT refuses to say certain people's names, no matter what. And it's for the best engineering reason ever: regexes.
Yep, you heard that right. ChatGPT's internal code has regexes looking for specific names and throwing an error anytime it sees them coming out of ChatGPT directly.
The oldest security measure in the book
What's the oldest and best security measure? Regexes, of course. But why are they even doing this?

It turns out these are people who tried to sue OpenAI. So how can you get in any more trouble with ChatGPT making up lies about people? Simple: just never allow ChatGPT to mention that person's name. Ever. No matter what.

But isn't that terrible engineering?
Sure, you might say, "Wow, what terrible engineering. How disgusting." But really? What are they going to do instead?

Are they going to retrain a new model for millions of dollars just to not mention these few random people's names? And do that every time they're worried about lawsuits?
Or if someone's mounting a suit against you, are you going to let yourself continue to be liable to the same thing over and over?
Sometimes simple is best
It's easy to make fun of this approach, but it's such a simple, easy-to-leverage solution that they did in a pinch. Because it was a good idea.
Fun fact: the actual Builder.io codebase for our Figma to code product does literally the same thing. Yes, we have advanced machine learning, malicious content detection, yada yada.
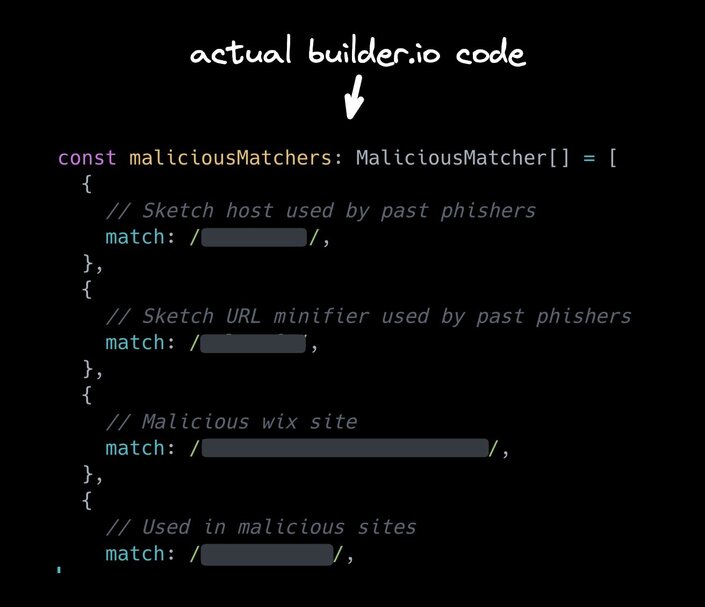
But sometimes when we see a very clear pattern that we need to just stop immediately, we just add it to an array of regexes and disable any content that matches. It's fast. It's cheap. It's effective.

Y'all, you don't have to over-engineer every single problem.
How strict are these regexes?
The regexes are pretty strict. If you had a dot in the name, if you had the person's middle initial or middle name in there, it's fine. It'll output it. But just first name, space, last name? No chance.
And the same goes for other names like this.
The power of regex
While AI hallucination is no new thing, and it's probably the number one problem that LLMs have had forever and probably will have for some time, at least we know when you can't fix it with the world's most advanced AI, you can always fix it with a regex.

Don't let anyone tell you in your pull requests that a regex is no good or a bad practice. The biggest, best, most innovative companies do it. And you should do it too.